

Again again, from the top
As a refresher, let's remind ourselves of the requirements of FizzBuzz
Write a method that takes a whole number and returns a text representation and has the following behavior for whole numbers above 0 (does not include 0). We don't have to add any bounds checking in this.
1. Return the string form of the number
* 1 as input returns "1"
2. If input is a multiple of 3 return "Fizz"
* 6 as input return "Fizz"
3. If input is a multiple of 5 return "Buzz"
* 10 as input return "Buzz"
4. If input is a multiple of 3 and 5 return "FizzBuzz"
* 30 as input return "FizzBuzz"
and we're technically still working on 3. If input is a multiple of 5 return "Buzz".
And let's refresh our flow chart for reference.
Since it's time for a new test, let's quickly validate that we're working a requirement and can come up with a test that'll fail. To get the next obvious multiple of 5, we'll just add 5 and get 10.
This means that Given 10, should get Buzz is a nice human language intent for this test. main c026027
In the last section we discussed practicing both styles of test method scaffolding. For our first test, we're using a Fresh Test, and subsequent tests we're using Copy Paste so that we can practice both. We showed that either gets us where we want to be. if you want to do just one of them for the practice - feel free!
For this practice, I'm copy and pasting this method main c839423 and then fixing up the contents main 1af26e3 and finally will update the name to match the test main 7b0484a which gets us to our failing test.
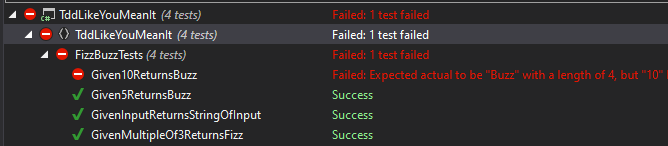
Which we can see is failing for the expected reason with an informative error message.
You may have noticed I make a commit for each step of updating the test. That's not an expectation when going through these practices, or in the work. I'm doing it here to provide an explicit history to make the practice visible.
I'm also pretty sure I mentiond that in an earlier chapter... Oh well
Next up is the condition for the input and returning what the assert expects.
Next Time
Is now. This test went... fast. There's not a lot to do. This tends to happen as you TDD into code. The time between tests shrinks a lot. You find and establish patterns that accelerate productivity. Even if those patterns aren't used next time, or even the next component - or as we've seen in some of the human language intent - The next test.
But the patterns let us move faster. The Refactor Phase is where we can be sure we have a time and place to keep everything aligned and following patterns/practices we want to see in the code.
Let's write our 3rd test for the 3rd requirement!
Next Test
From the top of the flow chart for a new test - we're working a requirement and can come up with a test that'll fail. To get the next obvious multiple of 5, we'll just add 5 to our last value 10 and get 15.
This means that Given 15, should get Buzz is a nice human language intent for this test.
Wait a minute - 15's called out in a future requirement; won't that make the test flakey?
You remembered.
If we wanted to have an opportunity to practice a flakey test, we absolutely should use 15. It's a good practice, and FizzBuzz grants us the ability to do so easily.
We should also practice paying some attention to known, but un-implemented, requirements allow us to not accidently create generalizations that we have to undo to extract the coming requirement. With FizzBuzz, as any practice, it's a simple thing and inclusion won't create much issue extracting later. More complex code easily can.
To avoid that, we'll go up one more 5 to 20. Given 20 should return Buzz main 779723c.
From there we will create the test scaffolding with Copy Paste main 0a21a63. Following the flow we update the contents main cc571e7 and finally the method name main 7d011a8.
We now have a failing test for our current intent for the expected reason from our informative message.
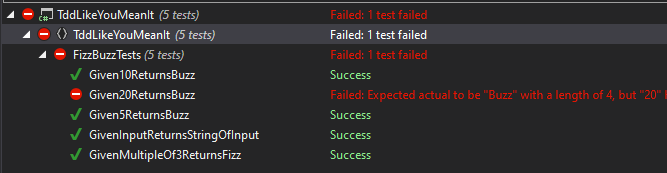
We get to do our simple condition for input to return the asserted expectation main 347155f.
And there's our passing test.
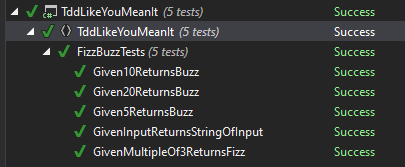
It was discussed in an earlier section about updating the code to reflect the intent of the values. Instead of 5, 10, 20, we show that they are multiples of 5. main 6f245bc
As that's a non-behavioral change, we continue to have passing tests, just like we want during a refactor phase.
And we get the code alignment that's so nice to see
public string Transform(int source)
{
if (source == 4 * 5) return "Buzz";
if (source == 2 * 5) return "Buzz";
if (source == 1 * 5) return "Buzz";
if (0 == source % 3) return "Fizz";
return source.ToString();
}
Since we know how to replace checks for multiple using a single operation, as evidenced by our handling of 3, we can add that line in. main a97819b
public string Transform(int source)
{
if (0 == source % 5) return "Buzz";
if (source == 4 * 5) return "Buzz";
if (source == 2 * 5) return "Buzz";
if (source == 1 * 5) return "Buzz";
if (0 == source % 3) return "Fizz";
return source.ToString();
}
Let's quickly comment out the lines main 4099290, and then remove them we stay green main f9662c1.
This puts us to a pretty concise form
public string Transform(int source)
{
if (0 == source % 5) return "Buzz";
if (0 == source % 3) return "Fizz";
return source.ToString();
}
Refactor
The first refactor I've been enjoying once a test is done is to remove the human language intent. Our test name reflects this, so we don't need it any more main 76c77e7.
As we're following patterns, we should probably create a version of the random test for our multiples of 5. Coincidently, the same multiple numbers showed up. 1, 2, 4. main a282104
[TestMethod]
public void GivenMultipleOf5ReturnsFizz()
{
//ARRANGE
Dictionary<int, string> regressionValues = new()
{
{ 1 * 5, "Buzz" },
{ 2 * 5, "Buzz" },
{ 4 * 5, "Buzz" }
};
(int sourceInput, string expected) =
regressionValues.ElementAt(new Random().Next(0, regressionValues.Count));
//ACT
string actual = Transform(sourceInput);
//ASSERT
actual.Should().Be(expected);
}
And then we can confidently remove the value specific tests. main 9a245bd
Something that was itching at my mind during the last round has come up again, and I think there's a pretty good solution.
As we can see in our MultipleOf5 test, the 5 and "Buzz" is repeated on every line. if we had to change the multiple value, or the response, we'd have to update every line. They change for the same reason. We should make anything changing for the same reason to have only a single place to change.
Simple enough to extract these out into variables. Our tools do that very well for us. main feb46d1
I use the term multiplicand because... I'm a giant nerd and I like using accurate math terms. Any name you choose that conveys intent for you and your team is great. In production code when I'm working with others, there's VERY few places I will use these terms. Normally only in objects whose responsibility is, like this case, multiplication.
If I'm working with others, I normally get "No, use BLAH instead" and I will without any resistance. The teams collective understanding is paramount.
Now that we've extracted both parts from our dictionary definition main b1146ef we can see some... duplication.
Why does our constant return value need to be defined, added to a dictionary, and then extracted... That's ... a lot of elements that aren't required. We can minimize the elements here by not having the expected value flow through the dictionary. main c96af78
[TestMethod]
public void GivenMultipleOf5ReturnsFizz()
{
//ARRANGE
int multiplicand = 5;
string expected = "Buzz";
Dictionary<int, string> regressionValues = new()
{
{ 1 * multiplicand, expected },
{ 2 * multiplicand, expected },
{ 4 * multiplicand, expected }
};
(int sourceInput, string _) =
regressionValues.ElementAt(new Random().Next(0, regressionValues.Count));
//ACT
string actual = Transform(sourceInput);
//ASSERT
actual.Should().Be(expected);
}
Since we haven't removed the dictionary yet, it's still there, but it's not used in the assert.
Instead of a dictionary, seems like we could just do a list now. main 2dd9995
[TestMethod]
public void GivenMultipleOf5ReturnsFizz()
{
//ARRANGE
int multiplicand = 5;
string expected = "Buzz";
List<int> regressionValues = new()
{
1 * multiplicand,
2 * multiplicand,
4 * multiplicand
};
int sourceInput =
regressionValues.ElementAt(new Random().Next(0, regressionValues.Count));
//ACT
string actual = Transform(sourceInput);
//ASSERT
actual.Should().Be(expected);
}
We still have some duplication; we multiple by the multiplicand for each value. What if we just use the 1, 2, 4 and do the multiplication when creating the value for sourceInput. main ff60c09
[TestMethod]
public void GivenMultipleOf5ReturnsFizz()
{
//ARRANGE
int multiplicand = 5;
string expected = "Buzz";
List<int> regressionValues = new(){1,2,4};
int sourceInput =
regressionValues.ElementAt(new Random().Next(0, regressionValues.Count))
* multiplicand;
//ACT
string actual = Transform(sourceInput);
//ASSERT
actual.Should().Be(expected);
}
The inline random has started to really bother me. Let's pull that out as a class field main df129c9. I didn't manually go change the other tests, ReSharper identifies duplication of what is being extracted and offers to extract multiple instances. Do that if it's available. When it's not, I finish the flow I'm going through, then go edit the other tests. What I'm trying may not work, and it's easiest to just un-fix one test.
And then we can update the test to get the random index into a variable. main c2516e3
[TestMethod]
public void GivenMultipleOf5ReturnsFizz()
{
//ARRANGE
int multiplicand = 5;
string expected = "Buzz";
List<int> regressionValues = new() { 1, 2, 4 };
int randomIndex = rand.Next(0, regressionValues.Count);
int sourceInput = regressionValues.ElementAt(randomIndex) * multiplicand;
//ACT
string actual = Transform(sourceInput);
//ASSERT
actual.Should().Be(expected);
}
And since we're building up the sourceInput from pieces, I think it'd make sense to move the regressionValue extraction into a variable. main 2db0cbe
[TestMethod]
public void GivenMultipleOf5ReturnsFizz()
{
//ARRANGE
int multiplicand = 5;
string expected = "Buzz";
List<int> regressionValues = new() { 1, 2, 4 };
int randomIndex = rand.Next(0, regressionValues.Count);
int elementAt = regressionValues.ElementAt(randomIndex);
int sourceInput = elementAt * multiplicand;
//ACT
string actual = Transform(sourceInput);
//ASSERT
actual.Should().Be(expected);
}
elementAt isn't a very good name. Since we have multiplicand.... multiplier is a great other name... in my giant nerdy opinion. main 342c964
[TestMethod]
public void GivenMultipleOf5ReturnsFizz()
{
//ARRANGE
int multiplicand = 5;
string expected = "Buzz";
List<int> regressionValues = new() { 1, 2, 4 };
int randomIndex = rand.Next(0, regressionValues.Count);
int multiplier = regressionValues.ElementAt(randomIndex);
int sourceInput = multiplier * multiplicand;
//ACT
string actual = Transform(sourceInput);
//ASSERT
actual.Should().Be(expected);
}
With the variable being called multiplier it doesn't make a lot of sense for a collection of multipliers to be called regressionValues. It's not even the regression values any more. Once we extracted the multiplicand out, it ceased being an accurate name.
Since it's a collection of multipliers... multipliers seems pretty good.
Except I'm iffy on pluralizing for collections. It's too similar for things that are quite different. While I'm not convinced this is the way to go, I've started to suffix collections with Collection. Unfortunately in C# this strongly implies it's an implementation of the Collection interface, which isn't too far off. Since we have a List, that does implement Collection.
I don't want to suffix List since most of the time the type of collection doesn't matter. Since this is a test, and it is being a list... I'll give in and suffix it. Giving us multiplierList. main 4da73fc
[TestMethod]
public void GivenMultipleOf5ReturnsFizz()
{
//ARRANGE
int multiplicand = 5;
string expected = "Buzz";
List<int> multiplierList = new() { 1, 2, 4 };
int randomIndex = rand.Next(0, multiplierList.Count);
int multiplier = multiplierList.ElementAt(randomIndex);
int sourceInput = multiplier * multiplicand;
//ACT
string actual = Transform(sourceInput);
//ASSERT
actual.Should().Be(expected);
}
Definitely a few more variables floating around. I think it reads better. We have code that tells us what it's doing much more effectively. It is clearly expressing it's intent through variable names. We don't need to parse the code to understand what's being done - The variables tell us.
If we check the docs on Random#Next we don't need the 0. It defaults to zero. There's an element we can minimize. main 122def1
As you can see, the refactor phase is less a flow, more of a buffet. Pick the one you want to do next, and keep repeating until you're comfortable moving on.
Since we're following a flow chart... it's a little "flow" focused.
Let's update our MultipleOf3 test to have this new pattern. main 8bb5de1
[TestMethod]
public void GivenMultipleOf3ReturnsFizz()
{
//ARRANGE
int multiplicand = 3;
string expected = "Fizz";
List<int> multiplierList = new() { 1, 2, 4 };
int randomIndex = rand.Next(multiplierList.Count);
int multiplier = multiplierList.ElementAt(randomIndex);
int sourceInput = multiplier * multiplicand;
//ACT
string actual = Transform(sourceInput);
//ASSERT
actual.Should().Be(expected);
}
What out the first test?
[TestMethod]
public void GivenInputReturnsStringOfInput()
{
//ARRANGE
Dictionary<int, string> regressionValues = new()
{
{ 1, "1" },
{ 2, "2" },
{ 4, "4" }
};
(int sourceInput, string expected) =
regressionValues.ElementAt(rand.Next(0, regressionValues.Count));
//ACT
string actual = Transform(sourceInput);
//ASSERT
actual.Should().Be(expected);
}
I'm against changing this one. While our tests are no longer very similar - We can't extract this one and maintain the things we should in a test.
If we don't include the expected result with the input, we'd have to "create" the expected result... using the same code the code under test uses. That's something we need to avoid.
We could get close to similar using 2 lists... but... The tests are doing slightly different things. Two are validating against a comment response, and this one is validating against varying responses. Since the test behavior has some variation... nay, some difference - we should make those differences more different. The test structure being different like this gives us that.
We'll leave it as it helps show us there's something different with that test from the other tests.
Shared Test Methods
If we look at our two multiple tests... There's A LOT of duplication. Since we changed one test to look like the other, it seems to be changing for the same reason - which is when know it's duplication and should refactor it out.
I, would not. It's a little on the preference side.
Test should be wholely self contained. Any calls to shared utility should be SO utility that it'd make sense in a common library for any number of test suites, not just these few tests.
Strong opinions, loosely held.
I have a very strong preference for the test to have all of the functionality it needs, even if it has duplication. Unless, as stated, it's such a general thing it'd be impossible to tie back to where it's been extracted from.
The commonality here
List<int> multiplierList = new() { 1, 2, 4 };
int randomIndex = rand.Next(multiplierList.Count);
int multiplier = multiplierList.ElementAt(randomIndex);
int sourceInput = multiplier * multiplicand;
Is very specific to the functionality/method under test. It's not something I'd extract.
What if we did? What'd that look like? It's almost always beneficial to work through and see what the thing you don't want to do looks like. Maybe something's changed.
In pairing/mobbing and there's multiple ideas - Do Them All. Time box the effort and do each persons idea. Often there's a clear winner. When there's not; let the person on the lowest power dynamic have their idea be the one implemented, with them as the navigator. There's a little more details, but that's a good summary of the approach to who's idea to use.
What's it look like with a method extracted?
[TestMethod]
public void GivenMultipleOf5ReturnsFizz()
{
//ARRANGE
int multiplicand = 5;
string expected = "Buzz";
int sourceInput = SourceInput(multiplicand);
//ACT
string actual = Transform(sourceInput);
//ASSERT
actual.Should().Be(expected);
}
private static int SourceInput(int multiplicand)
{
int randomIndex = rand.Next(multiplierList.Count);
int multiplier = multiplierList.ElementAt(randomIndex);
int sourceInput = multiplier * multiplicand;
return sourceInput;
}
And... I see an issue. The multiplierList being in here FORCES us into specific multiples. If we don't include that
[TestMethod]
public void GivenMultipleOf5ReturnsFizz()
{
//ARRANGE
int multiplicand = 5;
string expected = "Buzz";
List<int> multiplierList = new() { 1, 2, 4 };
int sourceInput = SourceInput(multiplierList, multiplicand);
//ACT
string actual = Transform(sourceInput);
//ASSERT
actual.Should().Be(expected);
}
private static int SourceInput(List<int> multiplierList, int multiplicand)
{
int randomIndex = rand.Next(multiplierList.Count);
int multiplier = multiplierList.ElementAt(randomIndex);
int sourceInput = multiplier * multiplicand;
return sourceInput;
}
Is there a lot of value to this? I don't see it.
Is there costs? Ehh... Refactoring tests will be a little constrained around it. If we make a change here, we may not know what else will be impacted.
The largest danger I see is that having this could drive early implementation of randomization into triangulation before it's ready to be done. These "common code" methods are usually not Duplicative. Even those they seem really like they fit the definition.
If this was non-test code, yes. Extract the method. Test code plays by slightly different rules. Some things are less emphasized. Duplication is a big one.
When we extract out commonality like this, we start to tightly couple our tests. The more code we extract, the tigher we couple our tests. The harder it is to refactor individual tests which makes it harder to safely refactor code.
I have some helper classes for testing - but you'd never be able to identify the code they came from. They're so independent, I have them packaged and use them in multiple projects. That's the level of value and lack of coupling I need to see before I want test code extracted for use in multiple places.
This is the type of discussion we have in mobs. We want to find the reasons and thoughts for preferences. The pros and cons. The pitfalls. Working solo it's easy to "just do it" and continue on.
Practices like this allow us to take the time and think about these things when we're not trying to solve something.
Listen to the tool
ReSharper is great for helping fix up code to follow standards.
As you can see in the snippets after extracting out the random, the name is rand. It's extracted as a
private static readonly Random rand = new();
The C# norm is to capitalize static fields, so it becomes
private static readonly Random Rand = new();
It's a small thing the tool highlighted for me, and is definitely a change I'm making. main 238372f
There's a few other little things that the tool is suggesting. The hard coded values in the tests are being suggested to be made const. I normally do this... just to quite the noise main 22702c4.
Next Time
And now we're done with our third requirement. well... We're at least done with the refactor phase and back to writing a new test. Which will show us if we need to select a new requirement.