

A second requirement
As a refresher, let's remind ourselves of the requirements of FizzBuzz
Write a method that takes a whole number and returns a text representation and has the following behavior for whole numbers above 0 (does not include 0). We don't have to add any bounds checking in this.
1. Return the string form of the number
* 1 as input returns "1"
2. If input is a multiple of 3 return "Fizz"
* 6 as input return "Fizz"
3. If input is a multiple of 5 return "Buzz"
* 10 as input return "Buzz"
4. If input is a multiple of 3 and 5 return "FizzBuzz"
* 30 as input return "FizzBuzz"
and we're working on 2. If input is a multiple of 3 return "Fizz". This comes after some significant refactor of our triangulation tests for our first requirement that collapsed down into a single test.
We will continue to use input/expected explicit tests to triangulation into something for our second requirement. Using the same randomization form we refactor to is not as fast or informative as the explicit tests.
This is also all about the practice, so we want to practice doing these explicit tests as they are (IMO) the right way to go about TDD.
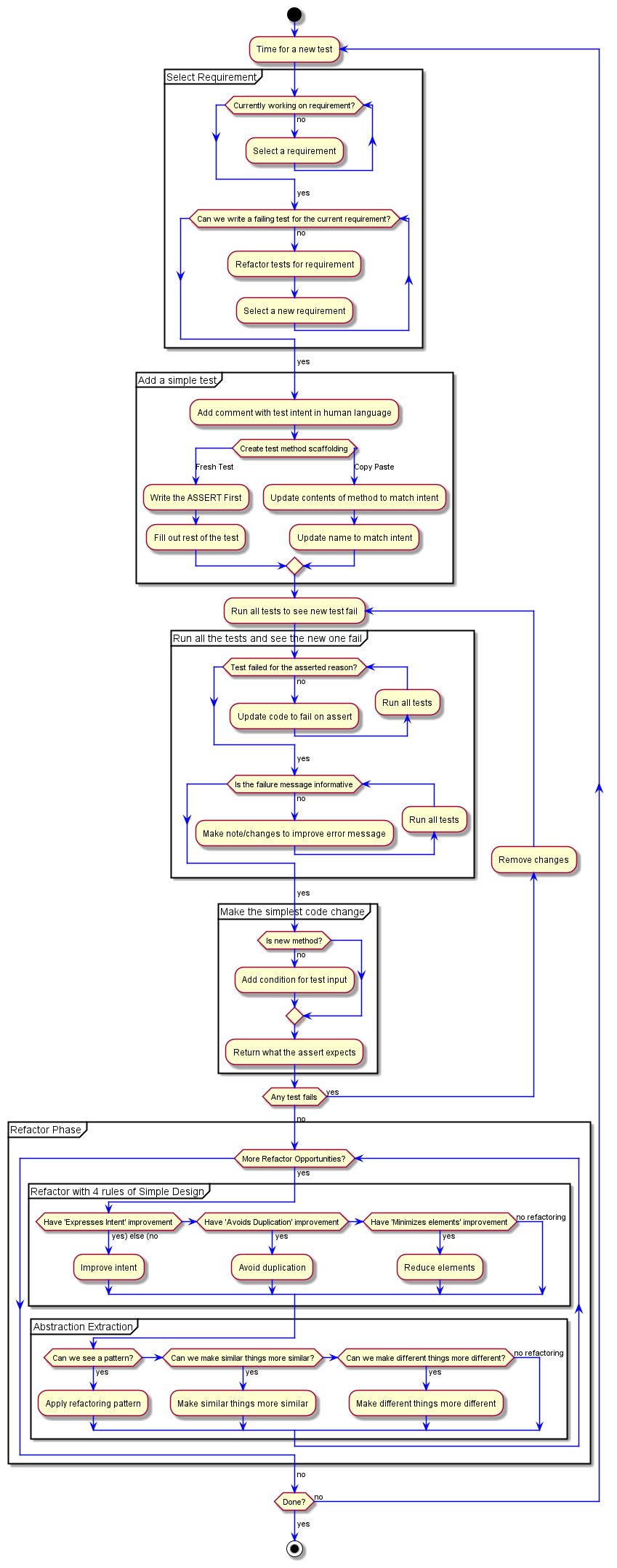
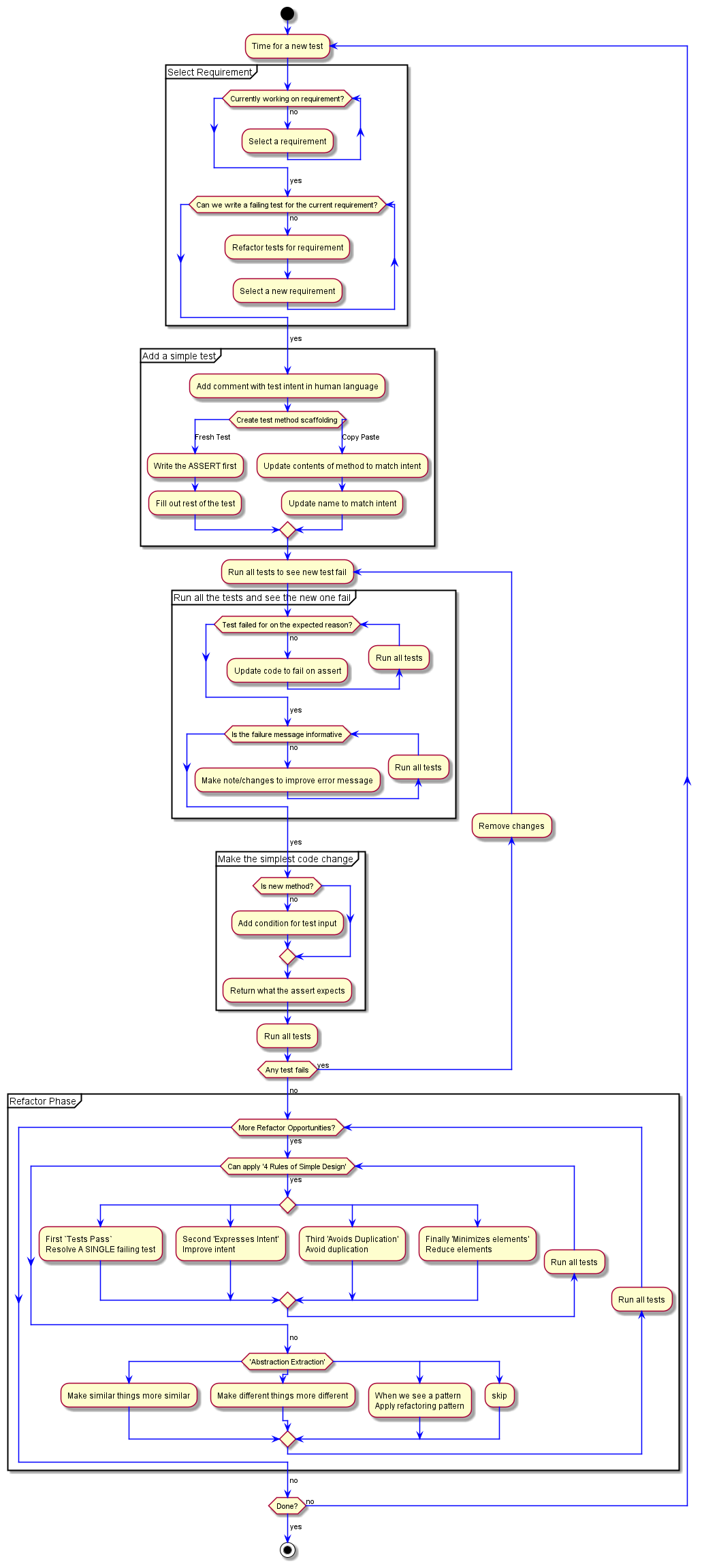
Let's find ourselves a failing test for this new requirement!...
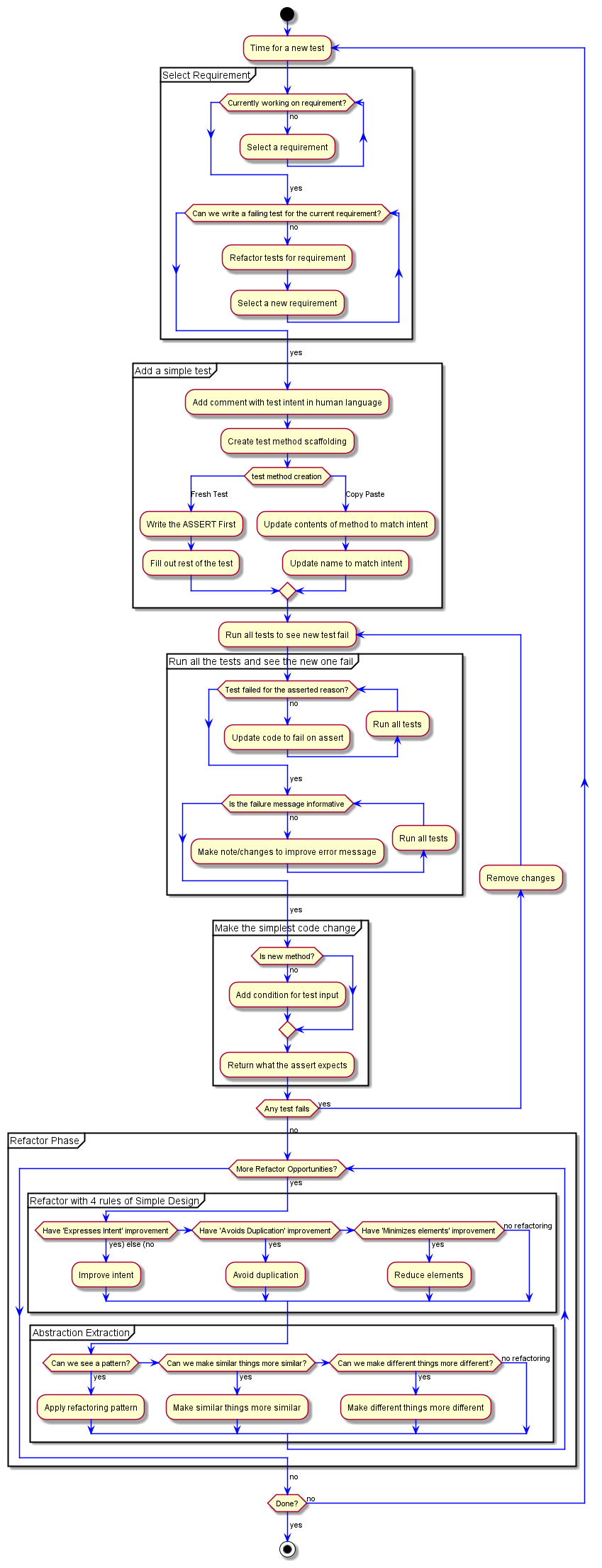
What is our test going to be? What human language can we use. Well... our requirement is If input is a multiple of 3 return "Fizz"... so... Pass in 3, get back "Fizz"?
Let's put that in as a comment so we have it to reference as we work on it.
//Pass in 3, get back "Fizz"
You may notice that this doesn't match what we had for our first "human language" comment - //Given an integer of 3 should return string of 3.
That's fine. Sometimes it's nice for the comments to be very similar, but they are temporary enough that we may not remember what we had before. I didn't. Which is why it's different.
The human language intent is just to help us as the individual, pair, or mob to know what we're trying to accomplish and have that reminder explicit in front of us.
With the comment written, we need a test to implement it.
With the tests for our first requirement being a combination of all our of previous tests; can't really Copy Paste. Time for a Fresh Test.
We ABSOLUTELY can type out the method attribute, and the method. Maybe give it a good name while we do that. Then type out the //Arrange, //ACT, //ASSERT. With apparently failing to keep the capitalization consistent, which we'd need to clean up... OR... OR - Use your tools and create a template. I'd wager that most IDE have some way to add a template for you.
I use ReSharper for my templates in Visual Studio. I've used ReSharper templates EXTENSIVELY on a project to save hundreds of hours of work. We had code with a lot of similarities, but just enough difference we couldn't abstract it. Literally saved hundreds of hours. Probably what allowed us to meet our deadline.
I'll write up a short blurb on ReSharper templates later, but here's what my template looks like
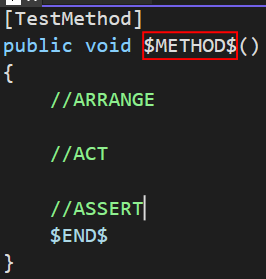
For those that like to copy/paste
[TestMethod]
public void $METHOD$()
{
//ARRANGE
//ACT
//ASSERT
$END$
}
When I invoke this template I get the following code
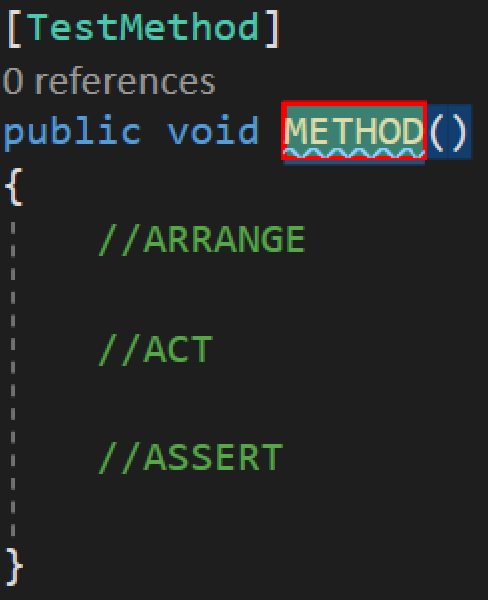
The red-box bounded part is a placeholder that when I start typing, will be replaced with whatever I type. You can see it in the template code as $METHOD$. Since we're creating a test and have an idea of what we want to do, we can name it something close. We can always refactor, so just go with the first thing you think of. Even something that you KNOW you'll have to change. Especially while the driver in mobbing. You have the power to name it, but can't take too long as the navigator is going to want to continue writing the test. We'll pretend we had a time constraint and typed In3OutFizz.
It's good enough to continue.
After we type that and hit enter (indicating we're done with the token replacement) our cursor goes to where the template has $END$. You'll notice that it's after //ASSERT. This put us right where we want to be so we can continue the flow chart and Write the ASSERT first.
What's our assert? Given 3, give back "Fizz".
[TestMethod]
public void In3OutFizz()
{
//ARRANGE
//ACT
//ASSERT
actual.should().Be("Fizz");d
}
I haven't mentioned it before... because I just thought about it - this style of writing code that doesn't exist yet. We're "programming by intent". We write what we want to exist, and the tools available to us are going to be able to help us. Write what you want to exist, and then use the tools to do as much as possible.
"Programming by Intent" is a way we can get fast feedback (which is why we're using TDD) on how we're interacting with the class under test.
It's not always going to be obvious, but it provides us a hook into what we want to see allowing the rest of the code we create to fill it in.
A lot of times when we jump straight to writing the code, we miss out on subtle things about how we will use that code. We miss friction points and frustrations that the consumers of the code may encounter.
And tools - Our tools can do a lot of the code generation for us. If for no other reason than speed of being able to get to the actual job - implementing functionality.
Much like our first test, I'm going to use ReSharper to generate the actual variable for me.

Tool Tip - CTRL+ALT+SHIFT+[Up Arrow] will move a line, or highlighted block, of code up a line. This is a convenient way to shift code around.
[TestMethod]
public void In3OutFizz()
{
//ARRANGE
//ACT
string actual;
//ASSERT
actual.Should().Be("Fizz");
}
As we did for our first test, and following the flow chart - We keep filling out the test method.
[TestMethod]
public void In3OutFizz()
{
//ARRANGE
//ACT
string actual = Transform(3);
//ASSERT
actual.Should().Be("Fizz");
}
And we run all of our tests to see it fail!

Looking closely we can see that it's failing due to "3" not being "Fizz". Which shows us the test is failing on the assert. We're not being fancy, so our assert message is pretty informative.
Which brings our flow chart to making the simplest code change! - Add condition for test input and Return what the assert expects. While two steps in the flow chart, we'll do them together.
public string Transform(int source)
{
if (source == 3) return "Fizz";
return source.ToString();
}
And we pass!
Fantastic! We can start applying the 4 Rules of Simple Design part of the flow chart.
We have an obvious Expresses Intent improvement with our test name. We can use the structure of the previous tests, GivenInput3ReturnsFizz.
And great. Sorta. The fact that a test failed is less ideal.

That means we have a problem somewhere. A tool supported refactor should not cause a failure like this. Especially since we renamed a test method. There's no step to fix a test during refactor. This means my flow chart is currently missing "run tests and make sure none fail" component. Which we'll add back in by putting the first of the "4 Rules of Simple Design" back in.
This is why we need to look at the failure message for any test we encounter. This one reads very close to our expected failure for this test method. "Fizz" and "3" are swapped thought.
The failing assert expected "3", and got "Fizz", which is definitely not our current test, and we can see that the test method is from our first test.
OF COURSE! And you've probably been shouting at me about it since I started this test. Well - What do we do?
We can't rollback since there were no code changes. We hit the horrific FLAKEY TEST!!!!
Let's go look at this failing test and you can tell me, "I told you so".
public void GivenInputReturnsStringOfInput()
{
Dictionary<int, string> regressionValues = new()
{
{ 1, "1" },
{ 2, "2" },
{ 3, "3" }
};
...
}
And here's our problem, {3, "3"}. We have a test that worked great... until new requirements came in.
This is expected. Our systems grow and evolve. The tests we write will change as the behavior of the system changes. It'll be quick like this one was or ages later for some minor small change.
This is what I like to call an unexpected test failure. This isn't going to go into the TDD flow; mostly because it doesn't support what I want it to do. I'll be switching to a different structure a little later to better get my ideas down.
For now, let's have a separate flow-chart of how to handle unexpected test failures. Since they're unexpected, we'll pretend there's no good place for it in the bigger flow chart.
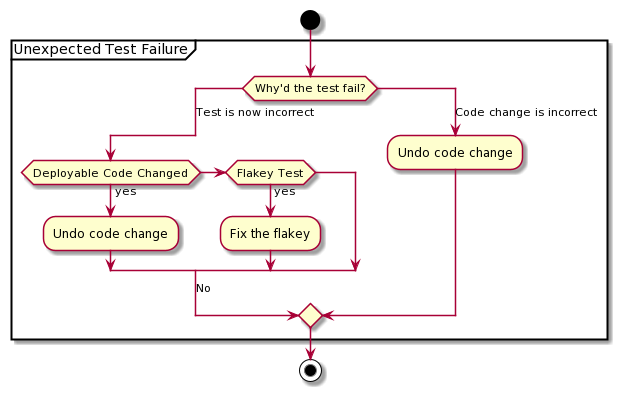
For us, the test failed because a requirement changed. And it's a flakey test.
So... Fix the flakey!
We can do a couple things to fix this. We can delete the {3, "3"}, but that'd defeat the purpose of keeping the level of testing that let us triangulate the general solution.
We can change the number. We could pick 4, or 5... Of course, we know we'd just run into this again if we tried 5. We can update the test to use {4, "4"} to maintain what we want out of the test.
I'm sure you can see that I intentionally set us up to encounter this. We need to be able to look at why a different test fails, and handle that appropriately. We don't want to reduce the value of the test, like deleting {3, "3"} would have. We want to know if it's the code or the test that's now incorrect. If it's code, just roll it back. If the test is now wrong; carefully identify why; in our case, a new requirement with a special case. Update the test to not expect the new edge case.
If you know up-coming requirements and can avoid writing a test that you know will fail in a couple minutes... then do so. When doing this practice I will normally do 1, 2, 4.
Just like for 3, I'm not going to... well... spoilers.
public void GivenInputReturnsStringOfInput()
{
Dictionary<int, string> regressionValues = new()
{
{ 1, "1" },
{ 2, "2" },
{ 4, "4" }
};
...
}
A question that often comes up is why the expected value in the test isn't4.ToString()?
It's much easier when we can have aninputvariable and ask "Why don't we useexpected = input.ToString()"?
The answer here is simple - We don''t want our expected answer to be dependent on code execution. We'd essentially have a test that asked, "Did the method return what the method returned?"
If we had a custom type, instead of an int, and overrode theToStringmethod with a bunch of clever code... and then replaced it all withreturn "1";. - What would the tests do?
They'd all pass.
In addition to being easy to be false positives; What is the expected value ofcustomType.ToString()?
You'll never know. If the code is updated and somehow a test breaks... what SHOULD the value have been? Is the test's first call toToStringwrong or the one in the production code?
When you are explicit about the value expected, debugging and reasoning about the test become much much easier.
Hard code your expected values, it 'Expresses Intent' much better.
//Pass in 3, get back "Fizz"
[TestMethod]
public void GivenInput3ReturnsFizz()
{
//ARRANGE
//ACT
string actual = Transform(3);
//ASSERT
actual.Should().Be("Fizz");
}
That was a fun tangent. But back to refactoring.
Right now I have the comment I want to delete and variables I want to extract. Following flow chart has me deleting the comment first to avoid duplication / minimize elements. Let's get that taken care of.
And now we can extract the input and expected into our //ARRANGE section.
[TestMethod]
public void GivenInput3ReturnsFizz()
{
//ARRANGE
string transformedValue = "Fizz";
int valueToTransform = 3;
//ACT
string actual = Transform(valueToTransform);
//ASSERT
actual.Should().Be(transformedValue);
}
One thing that I noticed about our variable names is that they are similar, but... different. The value part is just kinda swapped. How can we make these names more similar, or more different? Which would be better?
My inclination is to make them more similar. Seeing untransformedValue and transformedValue just appeals to me. But... they're different. We'd be unhappy if we selected the wrong one... ignoring the type difference.
Making them more different is going to help express our intent clearer.
Naming is something a mob is great for. Lots of ideas and inputs help us ensure the name is expressing our intent to an important group... the group working in the code.
I'm going to fall back to simplistic terms, sourceInput and expected. These are different things we've made more different. Which makes it easier to skim and not feel there's some kind of connection between the variables in the test.
I'm a fan of micro-commits. As you may have picked up on.
The re-name of our variable to expected is a commit main 7e2d7da and the rename of the input is another commit main e1a8de8.
[TestMethod]
public void GivenInput3ReturnsFizz()
{
//ARRANGE
string expected = "Fizz";
int sourceInput = 3;
//ACT
string actual = Transform(sourceInput);
//ASSERT
actual.Should().Be(expected);
}
Looking at these; why is onesourceInputand the other justexpected? Shouldn't it beinputandexpected? Maybe. I tend towards prefixing the parameter name from the method. Less work if the parameters change to keep the intent in place. Theexpectedvariable is singular due to the strong preference for a single assert. If we're only looking at one expected value, it is THE expected value.
We want our code to support the preferences we have for our code. If we only want a single assert, let's make it a little more annoying to have multiple.
Looking at the whole test class, we can see the previous names in the first test. We can refactor those to the new names as well.
In just as many commits as for the other test; main 10800a3 and main 96a9f60.
[TestMethod]
public void GivenInputReturnsStringOfInput()
{
//ARRANGE
Dictionary<int, string> regressionValues = new()
{
{ 1, "1" },
{ 2, "2" },
{ 4, "4" }
};
(int sourceInput, string expected) =
regressionValues.ElementAt(new Random().Next(0, regressionValues.Count));
//ACT
string actual = Transform(sourceInput);
//ASSERT
actual.Should().Be(expected);
}
There's one refactor that won't show up in the code. The file name. Our FizzBuzzTests class file is still called UnitTest1. Let's get that renamed to match the class.
Is there anything else to refactor? Yes. Can you find it? You might need to look at the code, or open it in an IDE to really see it.
It's hard to see... because it's whitespace. In the GivenInputReturnsStringOfInput above //ACT; there are 2 lines. That's an extra bit of white space; an extra line in fact. We need to look at these, and remove it. There's no purpose, value, or intent to having two lines here.
This is a code health. It's an important part of having high quality code. I can get a good idea of the quality of a code base by how many "cruft" whitespace lines there are. How many lines end with one or more space characters.
If you're not fixing the little things - I can't expect that you'll be fixing the big things. Every code base I've seen with lots of white space where it's not needed has quality issues.
Most IDEs have settings to adjust these types of things for you. Which is great, less work to keep code cruft out.
.editorConfig (https://editorconfig.org/) is a configuration that most major IDEs will use to configure code clean up (and much more) as part of the project files.
We'll add a Code Cruft section to our Refactor Phase. When you're getting ready to commit; also a great time to review your code changes and look for any extra lines sneaking in.
A quick delete and commit main d10c6cc and it's cleaned up.
A whole test!
That's the first test for our second requirement. We got through another round of the evolving flow chart. It's definitely improving and helping me stay explicitly on track to how I do TDD LIKE YOU MEAN IT.
Next Time
We're at the top of the flow chart; next time will be time for a new test!