

Triangulation Begins
As a refresher, let's remind ourselves of the requirements of FizzBuzz
Write a method that takes a whole number and returns a text representation and has the following behavior for whole numbers above 0 (does not include 0). We don't have to add any bounds checking in this.
1. Return the string form of the number
* 1 as input returns "1"
2. If input is a multiple of 3 return "Fizz"
* 6 as input return "Fizz"
3. If input is a multiple of 5 return "Buzz"
* 10 as input return "Buzz"
4. If input is a multiple of 3 and 5 return "FizzBuzz"
* 30 as input return "FizzBuzz"
and we're working on 1. Return the string form of the number
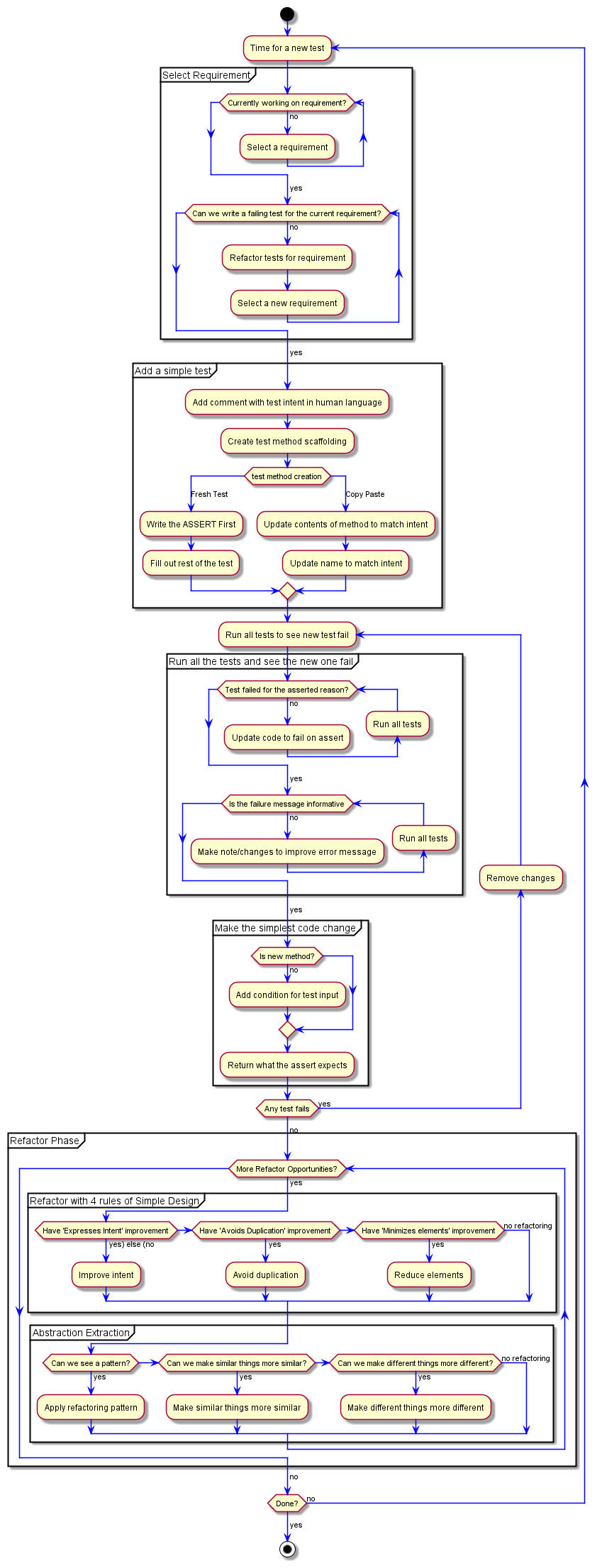
We're not done with our work, so back to the top of the flow chart we go
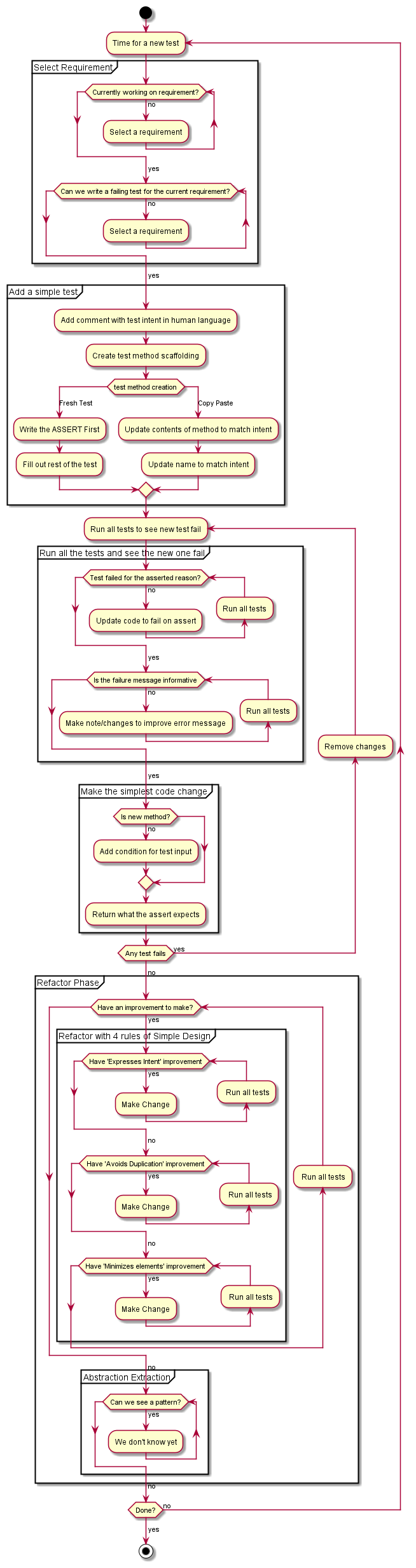
We're currently working on our first requirement.
Can we write a failing test? I bet we can. If we pass in 3, the code will return "1", which is definitely not the right answer.
The requirements say that "Fizz" is the right answer.
Is that the requirement we're working on? ... Not yet.
We treat this exercise as one requirement at a time. While it can definitely be valuable to keep known requirements in mind while working on other requirements, ignoring them for this exercise helps us encounter other things we need to be effective at doing.
Depending on what I'm trying to emphasize in a particular training session I'll suggest using 3 or 4 as the next input. In this case, I want to set us up to encounter some friction at a later point.
We can write another test for this requirement, using 3 as the input and expecting "3" as the output. This moves us into creating the test method scaffolding.
This has gotten a small update to better communicate the intent of this section.
Instead of waiting until we create the test method, we'll now add the new intent first. //Given an integer of 3 should return string of 3
We're once again using copy/paste.
This has the first change to be the contents.
//Given an integer of 3 should return string of 3
[TestMethod]
public void GivenInt2ShouldReturnString2()
{
//ARRANGE
int valueToTransform = 3;
string transformedValue = "3";
//ACT
string actual = Transform(valueToTransform);
//ASSERT
actual.Should().Be(transformedValue);
}
When there's more variation, I like to go bottom up. That way the last part is the name, and I'll be right there.
With our final result for the new method as
//Given an integer of 3 should return string of 3
[TestMethod]
public void GivenInt3ShouldReturnString3()
{
//ARRANGE
int valueToTransform = 3;
string transformedValue = "3";
//ACT
string actual = Transform(valueToTransform);
//ASSERT
actual.Should().Be(transformedValue);
}
Which gives us our wonderful red.
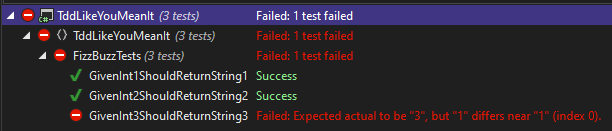
And we can see that it's failing for our asserted reason; Expected actual to be '3', but '1'. It's a good enough error message. We will know what the problem is if that ever breaks.
Since we do not have a method, let's add the condition for the test input and return what the assert expects.
public string Transform(int source)
{
if (source == 3) return "3";
if (source == 2) return "2";
return "1";
}
And we're green!
From the refactor phase using the 4 rules of simple design ; we can remove our comment with the intent in human language.
I don't see much else here that should be changed for these rules.
This moves us into the newer "Abstraction Extraction" section of our "Refactor Phase".
My favorite question to keep us slowed down until the code let's us know how to procede
Can we see a pattern?
Well... starting to. The two if lines in the method look REALLY similar. I like triangulation because it strongly implies we should have three points to be fully identify what the pattern is.
This is where I start to bring in "Make similar things more similar" which I get from Kent Beck. Which has the corellary of "Make different things more different". Getting these into the TDD flow chart had me make a few additional updates.
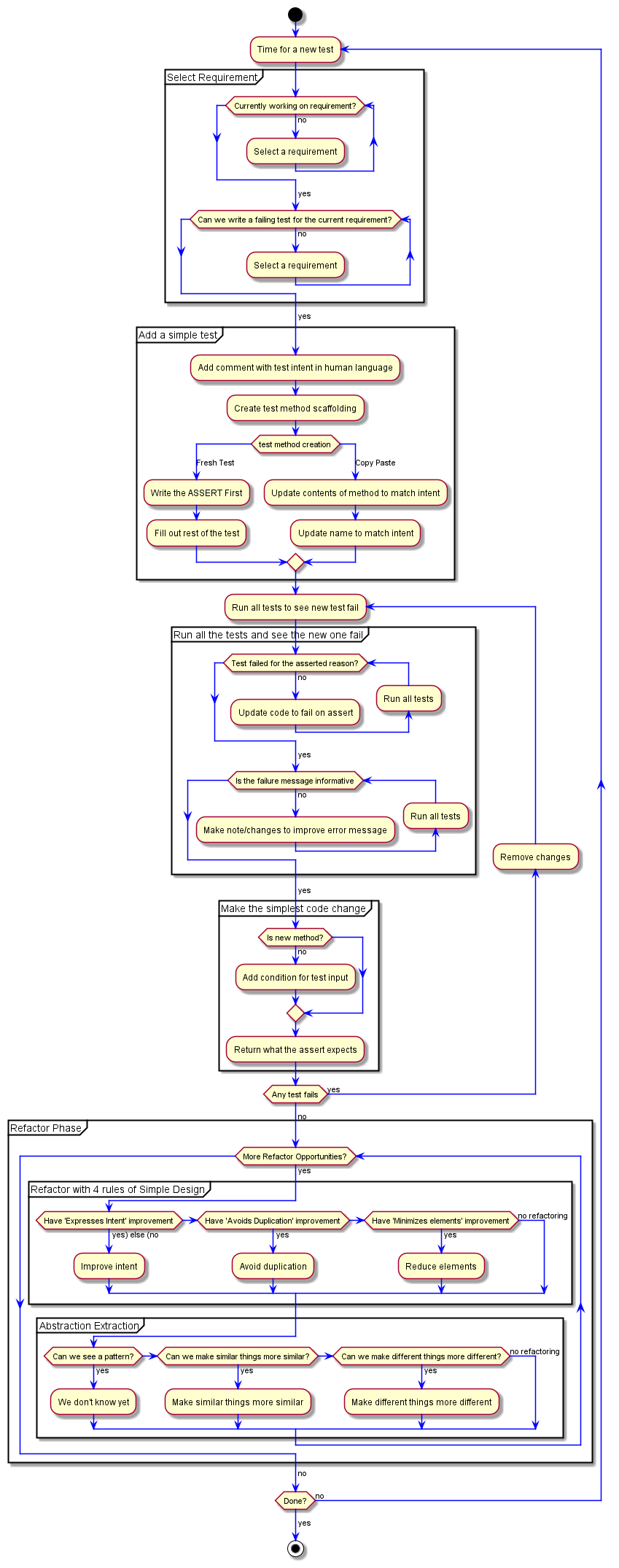
The piece I want to add the Make similar things more similar is for our return 1; line. While this is accurate, we can make it more similar to the other two lines. We have 3 nearly identical tests, but not 3 nearly identifical lines. Let's add one for our "1" reponse.
public string Transform(int source)
{
if (source == 1) return "1";
if (source == 3) return "3";
if (source == 2) return "2";
return "1";
}
We leave our existing code and add our new condition at the top. This is how we can guarantee our refactoring is not going to impact existing functionality; and if it does, we can get back to green instantly.
To make sure our new code is working; we can change the hard coded value of our return "1" line.
public string Transform(int source)
{
if (source == 1) return "1";
if (source == 3) return "3";
if (source == 2) return "2";
return "WE BROKE SOMETHING";
}
We could do a number of things here. Another option I go with a lot is throwing an exception. It's a little better for longevity purposes.
public string Transform(int source)
{
if (source == 1) return "1";
if (source == 3) return "3";
if (source == 2) return "2";
throw new Exception("We broke something");
}
The main reason I prefer exception is that it's clear something went wrong. Especially for more dynamic code. Just a return value... hard to see the intent. With an exception, we know something's not right.
A Pattern
And now we have a very clear pattern of what's going on. We check the number and return the value as a a string. We see this pattern; what do we do?
The simple answer is "generalize it". There's entire books on how to do this generalization. I won't flow chart that. Use Fowlers Refactoring [INSERT LINK STUFF] as the primary resource for ways we can improve any code we're working with; but especially TDD. I'm sure there are more... I'm too lazy to turn around and look at my piles of books.
We'll update the flow chart to just say "Apply refactoring pattern". Better minds than I have contributed a lot to these patterns; use their knowledge.
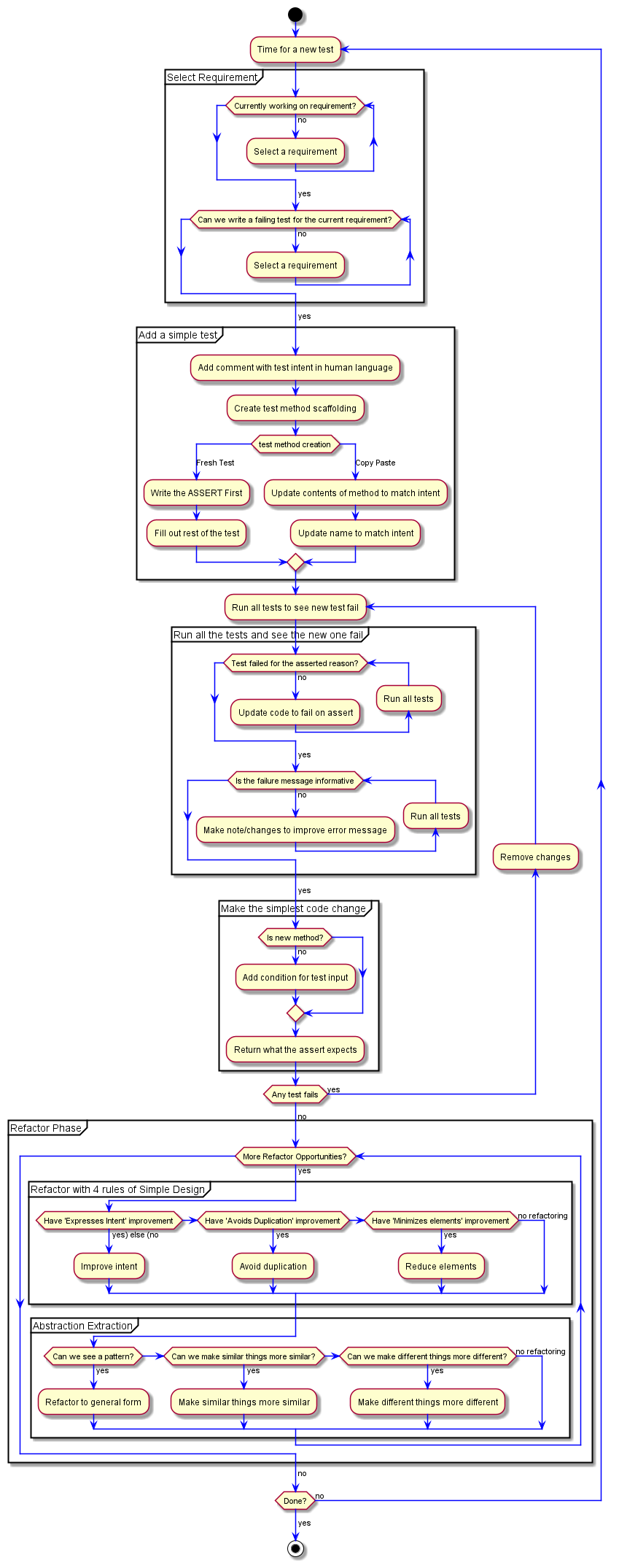
But what's our generalization? What's our pattern to apply?
As I wrote in the solution; C# has a ToString method. This normally works well for turning things into a string form. We can see if it'll work.
public string Transform(int source)
{
if (source == 1) return source.ToString();
if (source == 1) return "1";
if (source == 3) return "3";
if (source == 2) return "2";
throw new Exception("We broke something");
}
We use our generalization in a single case; and in a brand new implementation. If it didn't work; we just DELETE the line we added. We don't have to change any code we're confident about.
Since it works, we can comment out the next line.
public string Transform(int source)
{
if (source == 1) return source.ToString();
//if (source == 1) return "1";
if (source == 3) return "3";
if (source == 2) return "2";
throw new Exception("We broke something");
}
I like to use a comment just incase I screw something up. In this simple case... no. But if I have a more complex example, I can quickly uncomment the line and be back to green.
We are practicing. It's good practice to not remove working code until you have full confidence it's been replaced.
public string Transform(int source)
{
if (source == 1) return source.ToString();
if (source == 3) return "3";
if (source == 2) return "2";
throw new Exception("We broke something");
}
We quickly get to removing that line as our tests remain green.
Having seen that our generalized form works for one instance; we have a higher level of confidence it's going to work in another of our very similar lines. This is one of the values of making similar things more similar; we can have higher confidence if it worked in once place, it'll work in another.
To this end, I'm skipping the new line for using the general solution for 3.
public string Transform(int source)
{
if (source == 1) return source.ToString();
if (source == 3) return source.ToString();
if (source == 2) return "2";
throw new Exception("We broke something");
}
And we stay green. Using this confidence, let's apply this change to 2 as well.
public string Transform(int source)
{
if (source == 1) return source.ToString();
if (source == 3) return source.ToString();
if (source == 2) return source.ToString();
throw new Exception("We broke something");
}
I've slipped in a little. While we have been applying the generalization, we've made similar things MORE similar. This is exactly what a generalization is supposed to do. We saw a pattern, and used that to refactor the code to a more generalized for. Those refactorings have made the similar things more similar. A great result.
Now... for every input we have we now do the exact same thing. Let's use the 4 rules of simple design and avoid duplication and minimize elements.
public string Transform(int source)
{
if (source is 1 or 2 or 3) return source.ToString();
if (source == 1) return source.ToString();
if (source == 3) return source.ToString();
if (source == 2) return source.ToString();
throw new Exception("We broke something");
}
Of course we're not going to remove existing code; we're going to put in a new condittional for all of them. We've reduced our previous three if blocks into just one. We think. All of the tests are still green, but there's a chance we messed up; like if we didn't have that end or 3.
This is the same process we've used. Create the new code as early as possible in the method. Then comment out the code it should replace.
public string Transform(int source)
{
if (source is 1 or 2 or 3) return source.ToString();
//if (source == 1) return source.ToString();
//if (source == 3) return source.ToString();
//if (source == 2) return source.ToString();
throw new Exception("We broke something");
}
When we see that we're still green, we can now remove that code.
public string Transform(int source)
{
if (source is 1 or 2 or 3) return source.ToString();
throw new Exception("We broke something");
}
Since we expect this to be for every number, we can see that we'd just keep adding or # to the clause... it's for everything; meaning we don't even need the if. We should be able to just return source.ToString()
public string Transform(int source)
{
return source.ToString();
if (source is 1 or 2 or 3) return source.ToString();
throw new Exception("We broke something");
}
Ad we are green. We have some dead code now. When the IDE tells me the code is dead, which means it can't be executed, I'm OK skipping the comment out phase. Since we're green we can go ahead and delete those dead lines.
public string Transform(int source)
{
return source.ToString();
}
OK; let's cycle back to the top of our flow chart.
We're currently working on a requirement; Number to String. Can we write a failing test for the requirement?
... hmmm... Any number we provide... we'll get the string form back. Which means... No. Any test we write for this requirement will pass. We can't get a failing test for this requirement anymore.
The next step here is to Select a requirement but... we should address the tests for our current requirement. I don't like to muck about with the tests for the requirement I'm actively working on. Once we identify that we've gotten it to a place we can't write any more failing tests, we can look at how to clean up the tests.
Let's look at the tests for our first requirement all together
[TestMethod]
public void GivenInt1ShouldReturnString1()
{
//ARRANGE
int valueToTransform = 1;
string transformedValue = "1";
//ACT
string actual = Transform(valueToTransform);
//ASSERT
actual.Should().Be(transformedValue);
}
[TestMethod]
public void GivenInt2ShouldReturnString2()
{
//ARRANGE
int valueToTransform = 2;
string transformedValue = "2";
//ACT
string actual = Transform(valueToTransform);
//ASSERT
actual.Should().Be(transformedValue);
}
[TestMethod]
public void GivenInt3ShouldReturnString3()
{
//ARRANGE
int valueToTransform = 3;
string transformedValue = "3";
//ACT
string actual = Transform(valueToTransform);
//ASSERT
actual.Should().Be(transformedValue);
}
There's a lot of commonality here.
There's a couple of ways I like to ask a question about these tests?
- What's the difference path execution of the tests?
- When will they break separately?
Over all; the tests only serve a purpose if they'll break for a unique reason. If we mess up and all three tests fail; we'll focus on one of them and when that goes green... all go green. That means we're getting a lot more test failures then actual code failures. These tests are tightly coupled as they exectute the identical code paths.
Code must be maintained. More code is higher maintance costs. Even test code. Perhaps especially test code. When tests will fail and be fix for the exact reason; I don't find a lot of value in having multiple tests. There's definitely value in having multiple inputs tested. What can we do?
There's a few ways to do it.
Keep them
Despite the cost, keep all the tests that got you to the complete requirement. There are pro's and con's to all of these options. This one clearly shows the work that got the solution. It'll have multiple failures when it breaks, but... also maintains all the tests. So... Sure. This is definitely an option.
Of the two options I present and suggest to teams, this is one of them. I don't favor it, but will definitely do it if the team has a preference.
DataRow
One that I don't like is the [DataRow] attribute. If we were to use this to collapse these tests down it'd look like
[TestMethod]
[DataRow(1, "1")]
[DataRow(2, "2")]
[DataRow(3, "3")]
public void DataRowed(int valueToTransform, string transformedValue)
{
//ARRANGE
//ACT
string actual = Transform(valueToTransform);
//ASSERT
actual.Should().Be(transformedValue);
}
And it passes
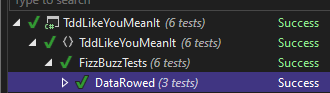
What if it fails? I'll change an expected result to force this.
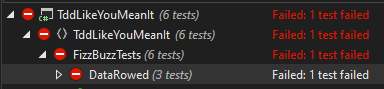
What'd I change? What broke? Yes; there is the chevron showing there's nested information - But, it's harder to find.

Expanding that out definitely shows us the failure. Maybe if I gave the test a better name...
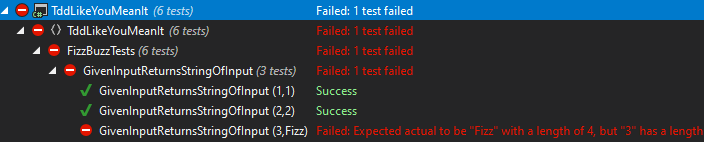
Nope. Still don't like it.
I've got issues with [DataRow] is where to stop? Why did we stop there? What if we want to just check some values, do we add them in? I feel that [DataRow] requires a lot more conventions to understand how they're being used and how to use them understandably.
We'll still have all these [DataRow] tests fail if there's a regression issue. And then all of them get magically fixed. That's not informative from a list of tests. We're maintaining and reviewing cruft. Tests that fail for the same reason shouldn't all exist.
If I won't leave each test that lead me to the generalized solution, I don't think [DataRow] is the correct answer. I've also seen [DataRow] so abused that no one knew how to detangle it.
With this test set up... We don't have a good distinction for what requirement is being tested. We could add every test imaginable for FizzBuss into the data rows for this single test (with a slight rename). It's too easily overloaded and makes no distinction for intent. Which makes violates the 2nd most important of our 4 rules of simple design.We can keep the tests passing and express intent by not using data rows.
Single Method
Another way that I've advocated for very heavily in the past is a single method.
We'll co-op the name and just have a single method that GivenInputReturnsStringOfInput.
[TestMethod]
public void GivenInputReturnsStringOfInput()
{
//ARRANGE
int valueToTransform = 1;
string transformedValue = "1";
//ACT
string actual = Transform(valueToTransform);
//ASSERT
actual.Should().Be(transformedValue);
}
This is essentailly our GivenInt1ShouldReturnString1 method renamed. Which... when we delete the other methods, correctly communicates the intent of this method. It's the test to show that when given an input, we return the string of the input.
While the functionality is the same, we have a "broader" intent for the method.
This is nice, but doesn't protect us particularly well. Even just the 3 tests help make sure we're not regression a few values. I will still do this one often. It's the norm on the teams I've been on; and the one I have a little more preference for over leaving all the tests to finish the requirement. I'm on the fence though. I leave it up to the team.
If the team doesn't have a convention, I try to poke them to this one.
Random
One of the things I've been starting to use is randomization.
[TestMethod]
public void GivenInputReturnsStringOfInput()
{
//ARRANGE
Dictionary<int, string> dict = new()
{
{ 1, "1" },
{ 2, "2" },
{ 3, "3" }
};
(int valueToTransform, string transformedValue) =
dict.ElementAt(new Random().Next(0, dict.Count));
//ACT
string actual = Transform(valueToTransform);
//ASSERT
actual.Should().Be(transformedValue);
}
A sharp observer may see that this has a lot of similarities to the [DataRow] option. There's some. What this is doing is providing a single test that can execute multiple input/expected pairs over the course of many test executions. If there's a failure, there's only going to be one test failing. Which is what I like to see.
The test has some additional complexity. This may not be obvious as to why, which we can work to improve the intent communication
Dictionary<int, string> regressionValues = new()
so it's the intent is clearer.
There's a risk to this structure - Flakey. If one of these pairs fail, we'll only see it a fraction of the time. The goal of these are that we're combining tests that are executing the exact same set of code; but as systems evolve we can't guarantee that.
Tests developed during TDD should run FAST and should all run very often. The flakey aspect of an change for one of these values should become quickly apparent. If it isn't... then the tests probably aren't being executed enough.
I'm going to stick with a randomization approach to test simplification. I'm having fun with it recently and until it annoys me enough or someone convinces me why I shouldn't... I'll lean towards it.
First Requirement Done
Now that we're done with out first requirement; we have some nice concise code
[TestMethod]
public void GivenInputReturnsStringOfInput()
{
//ARRANGE
Dictionary<int, string> regressionValues = new()
{
{ 1, "1" },
{ 2, "2" },
{ 3, "3" }
};
(int valueToTransform, string transformedValue) =
regressionValues.ElementAt(new Random().Next(0, regressionValues.Count));
//ACT
string actual = Transform(valueToTransform);
//ASSERT
actual.Should().Be(transformedValue);
}
public string Transform(int source)
{
return source.ToString();
}
Next time
In our next section we'll continue on our flow chart and pick a new requirement. We'll also get to see how to approach a change in requirements breaking an existing test.